Scalability Testing and Tuning¶
Determining the scalability of your cloud, and how to improve it, requires you to balance many variables. There are several aspects that can limit the scalability of a cloud, from the storage to the network Back-end, and no one solution meets everyone’s scalability goals. This guide firstly presents the scale limits of a single OpenNebula instance (single zone), and then provides some recommendations to tune your deployment for a larger scale.
The general recommendation is to have no more than 2,500 servers and 10,000 VMs managed by a single instance. Better performance and higher scalability can be achieved with specific tuning of other components like the DB, or better hardware. In any case, to grow the size of your cloud beyond these limits, you can horizontally scale your cloud by adding new OpenNebula zones within a federated deployment. The largest OpenNebula deployment consists of 16 data centers and 300,000 cores.
Scalability Testing¶
Front-end (oned) Scalability¶
This section focuses on the scale limits of oned, the controller component, for a single OpenNebula zone. The limits recommended here are associated with a given API load. You may consider reducing or increasing the limits based on your actual API requests. Notice that the maximum number of servers (virtualization hosts) that can be managed by a single OpenNebula instance strongly depends on the performance and scalability of the underlying platform infrastructure, mainly the storage subsystem. The following results have been obtained with synthetic workloads that stress oned running on a physical server with the following specifications:
CPU model: |
Intel(R) Core(TM) i5-3210M CPU @ 2.50GHz |
RAM: |
2x8GB, DDR3, 1600 MT/s |
HDD: |
KINGSTON SH103S3, SSD 240 GB |
OS: |
Ubuntu 19.10 |
OpenNebula: |
Version 5.12 |
Database: |
MariaDB v10.1 with default configurations |
In a single zone, OpenNebula (oned) can work with the following limits:
Number of hosts |
1,250 |
Number of VMs |
20,000 |
Average VM template size |
7 KB |
In production environments, we do not recommend exceeding in the same installation this number of servers (1,250) and VMs (20,000), as well as a load of 30 API requests/s to avoid the system becoming excessively slow. Better performance can be achieved with specific tuning of other components, like the database, or better hardware.
The four most common API calls were used to stress the core at the same time in approximately the same ratio experienced on real deployments. The total numbers of API calls per second used were: 10, 20 and 30. In these conditions, with a host-monitoring interval of 30 hosts/second, in a pool of 1,250 hosts and a monitoring period on each host of 180 seconds, the response times in seconds of the oned process for the most common XML-RPC calls are shown below:
Response Time (seconds) |
|||
API Call - ratio |
API Load: 10 req/s |
API Load: 20 req/s |
API Load: 30 req/s |
host.info (30%) |
0.04 |
0.24 |
0.31 |
hostpool.info (20%) |
0.25 |
0.57 |
0.66 |
vm.info (30%) |
0.06 |
0.26 |
0.33 |
vmpool.info (20%) |
2.39 |
4.68 |
6.36 |
Hypervisor Scalability¶
The number of VMs, micro-VMs or containers that a virtualization node can run is limited by the virtualization technology, hardware configuration and OpenNebula node components (drivers). In this section we have evaluated only the performance of OpenNebula, virtualization and monitoring drivers for the KVM, Firecracker and LXD. The host specs are the following:
CPU model: |
Intel(R) Xeon(TM) E5-2650 v4 @2.2GHz, 2 sockets 24 cores (HT) |
RAM: |
256GB, DDR4 |
HDD: |
480GB Micron M510DC SSD Raid - 420MB/s (r) 380MB/s(w) |
OS: |
Ubuntu 18.04 |
Hypervisor: |
Libvirt (4.0), Qemu (2.11), lxd (3.03) |
Virtualization Drivers: We have tested the ability of OpenNebula drivers to manage a given number of VMs. Note that the actual limits of the virtualization technologies are greater and the following tests do not try to assess these limits. OpenNebula is capable of managing the following number of VMs for each driver:
Hypervisor |
OS |
RAM |
CPU |
Max. VM/host |
Context |
VNC |
KVM |
None (empty disk) |
32MB |
0.1 |
500 |
SSH keys |
yes |
LXD |
Alpine |
32MB |
0.1 |
500 |
SSH keys |
yes |
FireCracker |
Alpine |
32MB |
0.1 |
1500 |
SSH keys |
yes |
Note: VMs were deployed in 100 chunks in all cases.
Monitoring Drivers: In this case we measured the time it takes the monitor driver to gather VM monitoring and state this information:
Hypervisor |
Total monitoring time |
Instance Monitoring time |
KVM |
52s (500 VMs) |
0.11s |
LXD |
48s (500 containers) |
0.10s |
Firecracker |
43s (1500 micro-VMs) |
0.03s |
Note: These values can be used as a baseline to adjust the probe frequency in /etc/one/monitord.conf.
Tuning for Large Scale¶
Monitoring Tuning¶
Following OpenNebula 5.12, the monitoring system uses TCP/UDP to send monitoring information to Monitor Daemon. This model is highly scalable and its limit (in terms of the number of VMs monitored per second) is bound by the performance of the server running oned and the database server. Read more in the Monitoring guide.
For vCenter environments, OpenNebula uses the VI API offered by vCenter to monitor the state of the hypervisor and all the Virtual Machines running in all the imported vCenter clusters. The driver is optimized to cache common VM information.
In both environments, our scalability testing achieves the monitoring of tens of thousands of VMs in a few minutes.
Core Tuning¶
OpenNebula keeps the monitoring history for a defined time in a database table. These values are then used to draw the plots in Sunstone. These monitoring entries can take up quite a bit of storage in your database. The amount of storage used will depend on the size of your cloud and the following configuration attributes in /etc/one/monitord.conf:
MONITORING_INTERVAL_HOST: Time in seconds between each monitoring cycle. Default: 180. This parameter sets the timeout to proactively restart the monitoring probe in the standardudp-pushmodel.HOST_MONITORING_EXPIRATION_TIME: Time in seconds before monitoring information expires. Default: 12h.VM_MONITORING_EXPIRATION_TIME: Time in seconds before monitoring information expires. Default: 4h.PROBES_PERIOD: Time in seconds to send periodic updates for specific monitoring messages.
If you don’t use Sunstone, you may want to disable the monitoring history by setting both expiration times to 0.
Each monitoring entry will be around 2 KB for each Host, and 4 KB for each VM. To give you an idea of how much database storage you will need to prepare, here are some examples:
Monitoring interval |
Host expiration |
# Hosts |
Storage |
|---|---|---|---|
20s |
12h |
200 |
850 MB |
20s |
24h |
1,000 |
8.2 GB |
Monitoring interval |
VM expiration |
# VMs |
Storage |
|---|---|---|---|
20s |
4h |
2,000 | 1.8 GB |
|
20s |
24h |
10,000 | 7 GB |
|
API Tuning¶
For large deployments with lots of XML-RPC calls, the default values for the XML-RPC server are too conservative. The values you can modify, and their meanings, are explained in /etc/one/oned.conf and the xmlrpc-c library documentation. In our experience, these values improve the server behavior with a large number of client calls:
MAX_CONN = 240 MAX_CONN_BACKLOG = 480
The core is able to paginate some pool answers. This decreases the memory consumption and in some cases makes the parsing faster. By default the pagination value is 2,000 objects but it can be changed using the environment variable ONE_POOL_PAGE_SIZE. It should be bigger than 2. For example, to list VMs with a page size of 5,000 we can use:
ONE_POOL_PAGE_SIZE=5000 onevm list
To disable pagination we can use a non-numeric value:
ONE_POOL_PAGE_SIZE=disabled onevm list
This environment variable can be also used for Sunstone. Also, one of the main barriers to scaling OpenNebula is the list operation on large pools. From OpenNebula 5.8 onwards, the VM pool is listed in a summarized form. However we recommend making use of the search operation to reduce the pool size returned by oned. The search operation has been available for the VM pool since version 5.8.
Scaling the API SERVER¶
In order to scale OpenNebula, it is recommended to balance client requests across multiple oned processes. This can be achieved by either using existing RAFT followers or adding oneds in an API server-only mode.
When oned is started in read-only (or cache) mode, it resolves any read-only operation by accessing the database directly. In particular, the following API calls are served directly by the server in cache mode:
one.vmpool.info
one.clusterpool.info
one.group.info
one.vmpool.accounting
one.zonepool.info
one.user.info
one.vmpool.showback
one.secgrouppool.info
one.datastore.info
one.vmpool.monitoring
one.vdcpool.info
one.cluster.info
one.templatepool.info
one.vrouterpool.info
one.document.info
one.vnpool.info
one.marketpool.info
one.zone.info
one.vntemplatepool.info
one.marketapppool.info
one.secgroup.info
one.imagepool.info
one.vmgrouppool.info
one.vdc.info
one.hostpool.info
one.template.info
one.vrouter.info
one.hostpool.monitoring
one.vn.info
one.market.info
one.groupool.info
one.vntemplate.info
one.marketapp.info
one.userpool.info
one.image.info
one.vmgroup.info
one.datastorepool.info
one.host.info
one.zone.raftstatus
Note
Read-only operations enforce any ACL restriction or ownership checks.
Any other API call is forwarded to the active oned process. In this case, the cache server is acting as a simple proxy. The architecture recommended to be used with the cache server is depicted in the following figure:
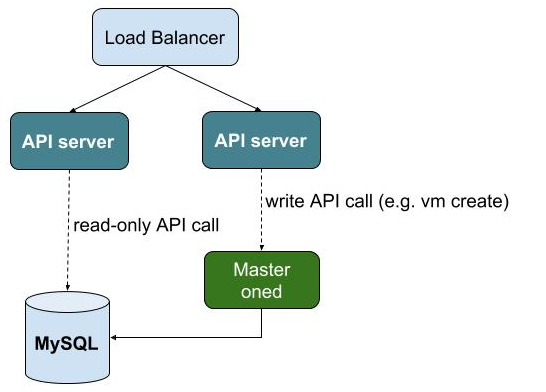
When the Master oned is actually a RAFT cluster, you can simply point the API servers to the VIP address of the cluster. Note also that the MySQL server in each RAFT server should be configured to listen to the VIP address to let the API servers query the database.
Configuration¶
To configure an API server you need to:
Install the OpenNebula packages in the server
Update the /etc/one/oned.conf file so it points to the master oned and Database:
DB = [ BACKEND = "mysql",
SERVER = "set IP of mysql server",
PORT = 0,
USER = "oneadmin",
PASSWD = "oneadmin",
DB_NAME = "opennebula",
CONNECTIONS = 50
FEDERATION = [
MODE = "CACHE",
ZONE_ID = 0,
SERVER_ID = -1,
MASTER_ONED = "set the XML-RPC endpoint of master oned"
Note also that you may need to tune the number of connections to the DB, increasing it for the MySQL server and adjusting the number of cache servers, considering that the overall number of connections is shared by all the servers.
Load Balancing¶
Alternatively, you may want to set up a load balancer that balances client requests across API servers. HAProxy is a good fit for this task. In this scenario, we are assuming one OpenNebula server plus two OpenNebula cache servers. The load balancer is listening on another server on port 2633 and will forward connections to the three OpenNebula servers comprising the cluster. This is the relevant fragment of the required HAProxy configuration for a scenario like the one described:
frontend OpenNebula
bind 0.0.0.0:2633
stats enable
mode tcp
default_backend one_nodes
backend one_nodes
mode tcp
stats enable
balance roundrobin
server opennebula1 10.134.236.10:2633 check
server opennebula2 10.134.236.11:2633 check
server opennebula3 10.134.236.12:2633 check
Server entries must be modified and the stats section is optional.
Optionally, a second load balancer can be added on another server and an active-passive redundancy protocol, like VRRP, can be set between both load balancer nodes for high availability.
To connect to the cluster from another server you can use one of the two following options, or both:
Using the CLI: Create a
ONE_XMLRPCvariable with the new endpoint. E.g.
export ONE_XMLRPC=http://ENDPOINT_IP:2633/RPC2
Using Sunstone: Modify
one_xmlrpcin /etc/one/sunstone-server.conf
The new endpoint will be the load balancer address.
Driver Tuning¶
OpenNebula drivers have by default 15 threads. This is the maximum number of actions a driver can perform at the same time; all following actions will be queued. You can make this value in /etc/one/oned.conf. The driver parameter is -t.
Database Tuning¶
For non-test installations use a MySQL/MariaDB database. SQLite is too slow for more than a couple of hosts and a few VMs.
Be sure to review the recommended maintenance procedures for the MySQL database backend.
Sunstone Tuning¶
Please refer to the guide on Configuring Sunstone for Large Deployments.